
工作中会用到阿里云的pyodps,经常调用pandas的API,于是整理了这篇教程。我觉得pandas理清三个概念就够了——属性、方法、索引,记住常用的语句,其他的都可以现用现查。写pandas的时候思路可以按照写SQL的思路来,这样脑子才不会乱,即能够使用pandas实现:表的创建删除、增、删、改、查、分组、排序、表关联。
最后,在文中附上非常全的pandas文档、教程、数据分析项目链接,真的百分百够用了。
教程参考资料
datawhale :
仓库:https://github.com/datawhalechina
pandas:http://joyfulpandas.datawhale.club/Content/index.html
numpy:https://github.com/datawhalechina/powerful-numpy
matplotlib:https://datawhalechina.github.io/fantastic-matplotlib/pandas官网:
教程:https://pandas.pydata.org/docs/index.html
- 如果你之前学习过机器学习,肯定会知道西瓜书,和西瓜书配套的教程是南瓜书,这本书就是datawhale开源的。他们的数据分析(pandas、numpy、matplotlib)教程写的也是非常棒。

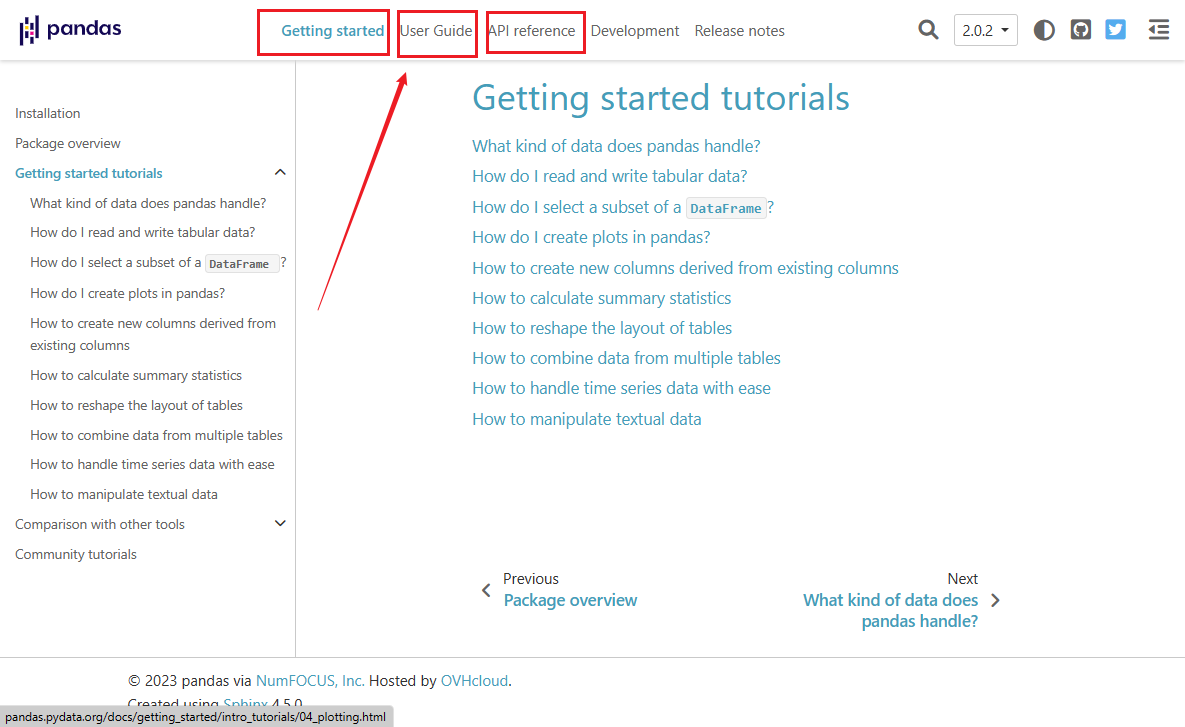
- pandas的官网教程写的也是非常详细,主要是三部分:getting start、user guide、api reference,熟悉了之后工作中用到什么就直接查api,非常方便,官方给了详细的示例。
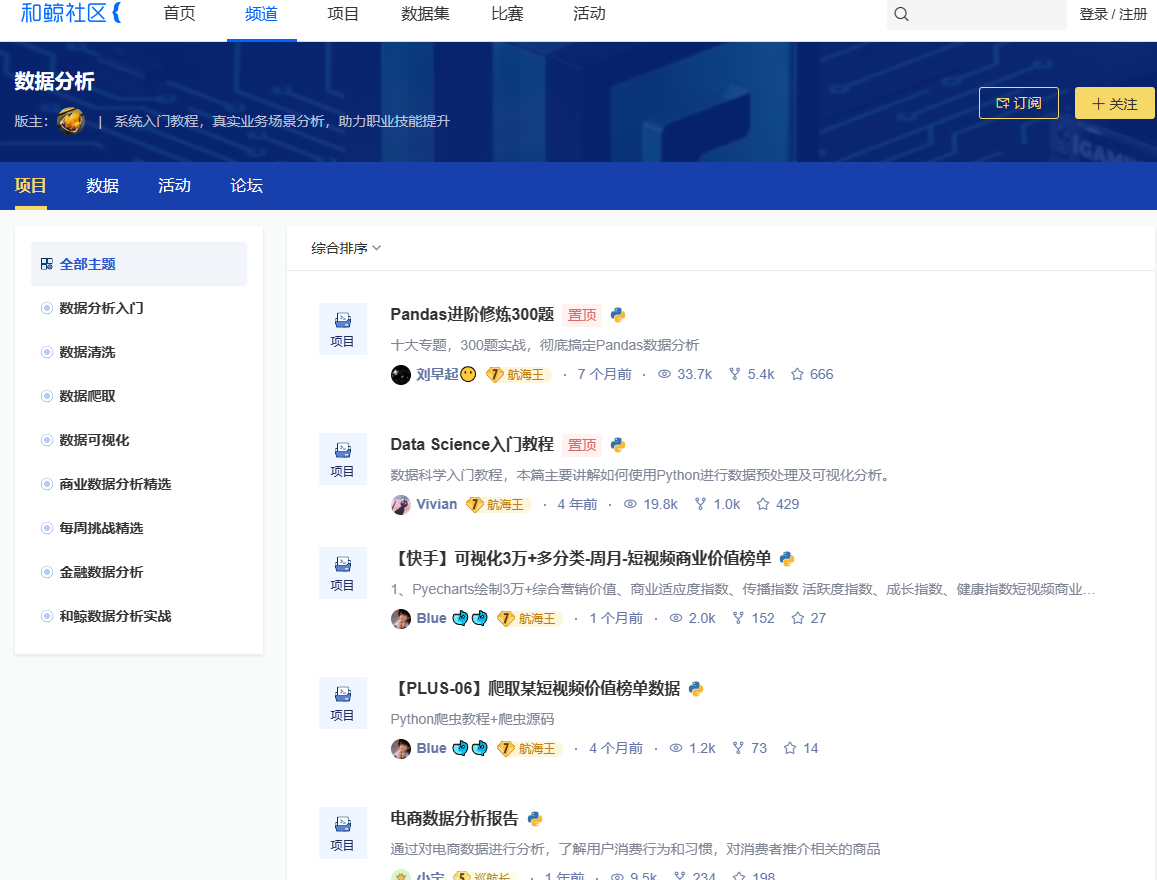
- 如果实际工作中如果没有项目用到pandas,可以在heywhale社区中找到许多项目供自己练习,并且也可以参考他人写的代码。
学完基础知识之后,可以试试kaggle的24道练习题测试以下自己是否掌握:
Pandas 24 useful exercises with solutions | Kaggle
- How to create a series from a list, numpy array and dict?
- How to combine many series to form a dataframe?
- How to get the items of series A not present in series B?
- How to get the items not common to both series A and series B?
- How to get useful infos
- How to get frequency counts of unique items of a series?
- How to convert a numpy array to a dataframe of given shape? (L1)
- How to find the positions of numbers that are multiples of 3 from a series?
- How to extract items at given positions from a series?
- How to stack two series vertically and horizontally ?
- How to get the positions of items of series A in another series B?
- How to compute difference of differences between consequtive numbers of a series?
- How to convert a series of date-strings to a timeseries?
- How to filter words that contain atleast 2 vowels from a series?
- How to replace missing spaces in a string with the least frequent character?
- How to change column values when importing csv to a dataframe?
- How to import only specified columns from a csv file?
- How to check if a dataframe has any missing values?
- How to replace missing values of multiple numeric columns with the mean?
- How to change the order of columns of a dataframe?
- How to filter every nth row in a dataframe?
- How to get the last n rows of a dataframe with row sum > 100?
- How to find and cap outliers from a series or dataframe column?
- How to reverse the rows of a dataframe?
numpy pandas 笔记
笔记代码地址:pandas基础知识笔记-Nikola (gitee.com)
numpy基础
数组有一维数组和多维数组,重点需要掌握数组的创建、数组的索引切片。
numpy 创建
形成的是一个numpy.ndarray对象。其实就是里面是一个列表或者列表里面包含列表。
- 直接列表构造
- 等差构造
- 随机构造
- 特殊数组
# array 直接构造
np.array(['a','b',1,2]) # 一维
np.array([[1,2,3],[4,5,6]]) # 多维
# 等差构造 np.arange
np.arange(1,10,3)
# 随机构造
np.random.randint(1,10,3)
# 特殊数组
np.zeros((3,4))
数组的变形、转置
- 转置
- 变形 reshape shape 两种方式
# 转置
np.zeros((3,4)).T
# 变形
# 方式一:
np.zeros((3,4)).reshape(2,6)
# 方式二 :
n =np.zeros((3,4))
n.shape= (6,2)
数组的索引和切片
切片,左闭右开 [start:stop:step]
- 一维数组
- 二维数组
- 利用数组索引数组
# 一维
n = np.arange(13,1,-1)
n[2]
n[-2]
n[1:3]
n[:4]
n[:4:2]
n[1:5:2]
# 二维
# n.reshape(3,4)
n.shape = (4,3)
n[2] # 只取到了第一层
n[1:3:2] # 步长为2
n[-1]
n[1,1] # 取到了第二层
# 利用数组索引数组
n1 = np.array([2,1]) # 取出索引为2,1的值
n[n1]
常用方法
- where # 指定满足条件与不满足条件位置对应的填充值
- any all # any存在一个 True 或非零元素时返回 True ;all 当所有为True时返回 True
- diff # 和前一个元素作差
- 创建空值 # np.nan
- 判断空值 # np.isnan()
- 统计函数 max min mean # 很多 只列出这几个
# where
n = np.array([-1,-3,-5,0,1,6,9])
np.where(n>0,n,-666) # n中的值大于0时,等于它本身,否则为填充值
# any all
n = np.array([-1,2,0]) # 存在一个0元素
n.any() # np.any(n) 两种写法都可以
# diff
n = np.arange(1,15,3)
np.diff(n)
# 统计函数 max min
n= np.array([0,3,7]) # 无空值时
n.max()
n= np.array([0,3,7,np.nan]) # np.nan 创建空值
np.isnan(n) # 判断空值
n.max() # 无法判断最大
np.nanmax(n) # 要使用nan**函数
pandas
pandas 两种基本的数据结构:series 、 dataframe
series 创建
- 字典
- 列表
- 字典+列表
- numpy 数组
# 字典
dict = {"a":1,"b":2,"c":3}
pd.Series(dict)
# 列表
list = [1,2,3,"a"]
pd.Series(list)
# 列表+字典
dl = {"a":[0,1,2],"c":["f",4]}
pd.Series(dl)
# numpy 数组
n = np.arange(1,10,2)
pd.Series(n)
Series 属性
- shape
- size
- index
- values
- dtype
n = np.random.randint(1,100,10)
s = pd.Series(n)
s.shape
s.size
s.index
s.values
type(s.values) # numpy.ndarray
s.dtype
Series 方法
- s.head()
- s.tail()
- s.info()
- s.append() # 括号里是series df = pd.concat([s1,s2],ignore_index=True)
- s.drop() # 删
- s[?] = ? # 改
- s.sort_values() # 排序
- s.groupby() # 分组
- s.to_list() # 转化成列表
- s.isnull() # numpy 中只能用np.isnan() , pandas中两者都可以用
- series.value_counts() # 每个元素个数
- series.count() # 元素个数总和
- series.unique() # 去重后的元素
- series.nunique() # 去重后的元素个数总和 。注意和 count()方法区别
- series.isin([xx,xx])
s.head()
s.tail()
s.info()
# 增 append . 添加的必须是series
s1 = pd.Series(np.array([1,2]))
# s.append(s1,ignore_index=True) # 索引ignore
pd.concat([s,s1],ignore_index = True)
# 删
series = pd.Series([1, 6, 6 ,3, 4, 5])
series.drop(2) # 删除的是对应的索引
series.drop([1,2])
# 改
series[4] = 666
series
# 排序
series.sort_values(ascending= False)
# 分组
# groupby()
# 转列表
series.to_list()
# 判断空值
series.isnull() # 注意区分numpy的np.isnan()
series.isna()
series.value_counts() # 每个元素个数
series.count() # 元素个数总和
series.unique() # 去重后的元素
series.nunique() # 去重后的元素个数总和 。注意和 count()方法区别
series.isin([1,6]) # 判断 某某值 是否在其中
Series 索引
- 显式索引
- 隐式索引
看得到的叫做显式索引。
注意:显式索引左闭右闭,隐式索引左闭右开
s = pd.Series(np.arange(2,11,3),index=["x","y","z"])
s["x"] # 显式索引
s[0] # 隐式索引
dataframe 创建
dataframe 是由series 组成,因此同创建series的方式相同
- 字典+列表创建
- numpy 创建
- 字典+numpy
# 字典创建
list1 = "hello the cruel world".split() # 列表
list2 = [100,200,300,400]
dict = {"word": list1,"num":list2} # 注意 :必须是列表!!!
df = pd.DataFrame(dict)
# numpy 创建1
np1 = np.arange(1,12)
np2 = np.arange(12,23)
data = [np1,np2]
df = pd.DataFrame(data)
# numpy 创建2
n = np.arange(1,13).reshape(3,4)
df = pd.DataFrame(data=n,columns=[f"u{i}" for i in range(1,5)],index=['index1','index2','index3'])
# 字典+numpy(series)
data ={"a":np.arange(1,5),"b":np.arange(6,10)}
df = pd.DataFrame(data)
dataframe 属性
- df.shape
- df.size
- df.columns
- df.index
- df.values
- df.dtypes
df = pd.DataFrame(data=np.arange(2,14).reshape(3,4),columns=["a","b","c","d"],index=["x","y","z"])
df.shape # (3,4)
df.size # 12
df.columns # Index(['a', 'b', 'c', 'd'], dtype='object')
df.index # Index(['x', 'y', 'z'], dtype='object')
df.values # 数组
df.dtypes
dataframe 方法
- df.head()
- df.tail()
- df.info()
- df.isin([x,x]) # 是否
- df.isnull()
- df.apend() # 增 类比成字典
- df.drop() # 删 在drop系列 axis = 1 列。
- df[“xx”].unique()
- df[“xx”].nunqiue()
- df[“xx”].value_counts()
df.head()
df.tail()
df.info()
df.isin([5,6])
df.isnull()
# 增 append
s = pd.Series([55,44,11,22],index= ['a', 'b', 'c', 'd'],name = "vv" ) # s.name = "v"
df = df.append(s) # 这里如果不忽视索引的话 就需要给一个name给series
# dataframe 和 dataframe concat
df1 = pd.DataFrame({"a":[22],"b":[33],"c":[44],"d":[55]},index= ['vvv']) # 注意 这里是dataframe 对应的是index。
pd.concat([df,df1])
s1 = pd.Series([111,222,333,444] )
s1.index = ['a', 'b', 'c', 'd'] # 这里需要设置series 的索引
df2 = pd.concat([df,s1.to_frame().T]) # s1.to_frame().T 这里需要将series转成dataframe再转置
# 增 增加一列
df2['e'] = range(5)
# 删
df2.drop("e",axis=1,inplace= True)
dataframe 读取行列
1.查看列:
df["col1"] # series
df[["col1]] # dataframe
df[["col1","col2"]] # 注意双括号
查看行:
loc 显式索引 左闭右闭
iloc 隐式索引 左闭右开
查看列
df2["a"]
df[["a"]]
# 通过布尔值取值
df[df["a"]<df["a"].mean()] # 取所有true
# 查看行
df.iloc[1] # 隐式
df.loc["y"] # 显式
# 同时取行和列
df.iloc[1,2] # 行 列
df.loc["y","c"] # 行列
df.loc["y",:] # 行 所有列
df.loc["y",["a","b"]] # 行 指定列
df.iloc[[0,1]] # 注意双括号
df.loc[["x","y"]]
df.iloc[0:2]
df.loc["x":"z"]
后面希望能有时间加上数据清洗的常用代码以及可视化的内容。
(PS:写教程太累了 看起来简单 实际上 自己写代码测试 、写知识点需要花费很长的时间 ,这次写教程我也发现最好的参考资料还得是官方文档,虽然是英文的,实际上文档非常易读。 )